Streams Reference Architecture
26 minute read
Streams is an event hub that facilitates exchange messages between devices, services, and applications, but it only supports container-based deployment.
The purpose of this guide is to share Axway reference architecture for the container-based deployment of a Streams solution on Kubernetes. It covers the architectural, development, and operational aspects of the proposed architecture.
Because Docker and Kubernetes are portable across on-premise environments and many cloud providers, most of the information in this guide should apply to those environments. However, specific AWS recommendations are also provided, as it is one of the most common deployment targets.
Deploying Streams using Docker containers orchestrated by Kubernetes brings tremendous benefits in installing, developing, and operating the solution. This guide describes all major areas in deploying and maintaining Streams, including:
- Physical and deployment architectures.
- Explanation and consideration for selecting underlying infrastructure components.
- Kubernetes considerations.
- Performance, logging, and monitoring aspects.
- Backup and recovery, including disaster recovery.
Target audience
The target audience for this guide is architects, developers, and operations personnel. To get the most value from this guide, the reader should have a good knowledge of Docker, Kubernetes, and APIs.
General Architecture
This section focus on general architecture in support of a Streams deployment on a dedicated Kubernetes cluster. It discusses architectural principles, as well as required and optional components.
There are many ways to deploy software on a Kubernetes cluster, but this guide shares Axway’s experience acquired from deploying Streams in a production environment.
When following these instructions, ensure to comply with the constraints described in each section.
Principles
Official tests took place in Kubernetes as the orchestration component. However, the Docker images are platform agnostic, so they can be deployed in other orchestration platforms, or even on docker-compose, although this is not recommended other than for testing purposes.
Kubernetes manages many important aspects of runtime, security, and operations. Besides Docker and Kubernetes, we use Helm charts to describe the entire deployment configuration. Using Helm provides an efficient way to package all configuration parameters for Kubernetes and Streams containers to be deployed with a single command.
Using Helm, you can:
- Alter default resources configuration (CPU / memory).
- Select which components to deploy.
- Set up container-based configuration.
Following, we show which configurations can be changed and how to change them.
In generic terms, Streams is deployed as a stack of three layer with different responsibilities.
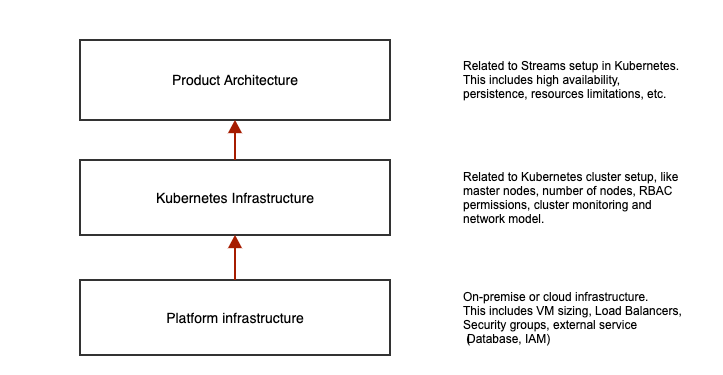
To help customers with setting up a required environment, the following table describes the required and recommended options.
| Description | Required? |
|---|---|
| A storage system with the capacity to store dedicated data and to share data between components | Required |
| A bastion for administration tasks on Streams and Kubernetes | Recommended |
| Kubernetes can pull Docker images from a Docker repository | Required |
| Docker images are pulled from a private proxy repository | Recommended |
Target use case
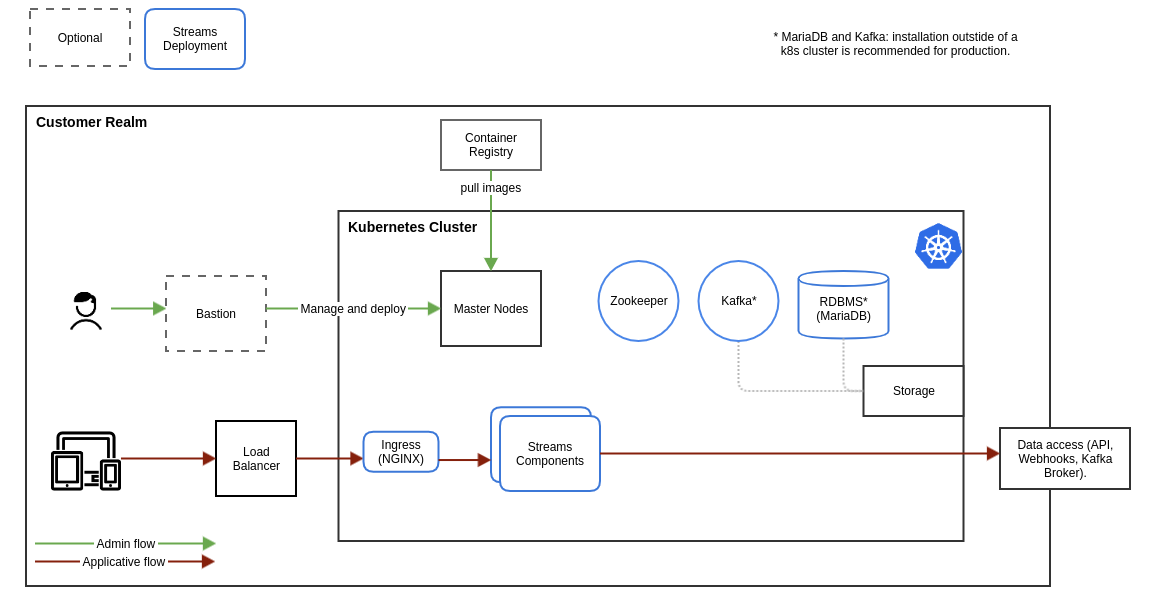
We reviewed a single deployment option where all Streams components, including their dependencies, are running inside a single Kubernetes cluster.
In our scenario, we expose several entry points for the external clients inside the cluster (see implementation details).
A dedicated deployment environment requires:
- A Kubernetes cluster.
- A Storage system .
- Access to Streams docker images in container registry.
The following diagram shows a general architecture of a single cluster configuration:
Additional components and considerations
In this section, we present the considerations for using additional components in the single cluster architecture.
Container proxy registry
To avoid your Kubernetes cluster to directly access internet, we recommend you to use self-managed docker registry proxy, for example, Sonatype Nexus, JFrog Artifactory. Then, you can configure this proxy to access the Streams images repository managed by Axway.
| Description | Type |
|---|---|
| Docker images contain sensitive data, such as certificate and configuration. This data must be protected. | Required |
| The password is sensitive and must be encrypted in the system. | Required |
Bastion host
Administrative tasks should be executed safely. We recommend you to use a bastion host to bridge to the following instances via the internet:
- Kubernetes master nodes for managing a cluster
- Kubernetes Dashboard
- RDBMS and Kafka
- Debugging any issue with a Kubernetes cluster
The bastion must have high traceability with specific RBAC permissions to allow a few selected users to access infrastructure components.
Storage capabilities
Platform infrastructure must support Kubernetes PersistentVolumes. For more information, see Volumes.
Encrypting volume data at rest
We recommend you to use an externalized Kafka, managed by a cloud provider, as opposed to an embedded Kafka. But, if you’re using an embedded Kafka, you must ensure that the volumes used are encrypted.
The encryption process depends on your cloud provider and Kubernetes setup. For example, if you are provisioning GP3 volumes on AWS, this means that you are using an AWS-specific driver, the aws-ebs-csi-driver. In that case, you can set a boolean parameter to true to activate the encryption, and the AWS console will display that your volumes are encrypted.
Encrypting secret data at rest
To improve security, you must encrypt K8s secret data at rest. See Encrypting Secret Data at Rest for more details.
Warning
We strongly recommend you to use a KMS provider instead of storing the raw encryption key in theEncryptionConfig file. Encrypting secrets with a locally managed key protects against an etcd compromise, but it fails to protect against a host compromise. Since the encryption keys are stored in the host, in the EncryptionConfig YAML file, a skilled attacker can access that file and extract the encryption keys.
Performance goals
An important factor for achieving your goals is to define a set of performance goals. These will be unique for a specific set of APIs, deployment platform and clients’ expectations. Later in this guide, we show an example of the performance metrics that have been achieved in testing a reference architecture.
Implementation details
This section describes the configuration for each component.
Diagram
The following diagram shows the recommended reference architecture diagram. It is designed with High Availability (HA) in mind.
An HA deployment requires redundancy and high throughput for all infrastructure components and networks. To reach this target, components must be deployed in multiple zones. If your K8s cluster is well-configured, the pods are spread across the zones in a best effort placement. To reduce the probability of unequal spreading across zones, it is recommended to use homogenous zone (same number and type of nodes) as designed in this architecture. In our configuration, we have used three availability zones. This configuration is compliant with a minimal technical SLA of 99.99 percent.
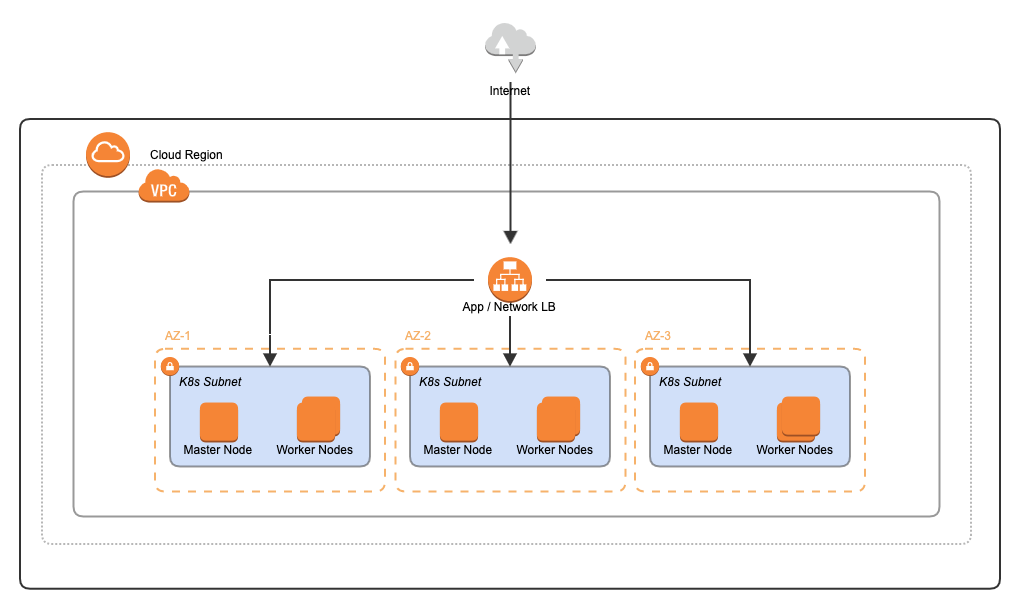
Choice of runtime infrastructure components
This section provides recommendations for a typical implementation of the runtime infrastructure components.
In this configuration, although the components are spread out in various racks, rooms, or available zones, all assets of the Kubernetes cluster are deployed in the same data center, or in a region (in case of a cloud deployment).
The following table lists the number of runtime components in this configuration.
| Assets | Spec |
|---|---|
| Master nodes | 3 (one per availability zones) |
| Worker nodes | 6 (two per availability zones) |
| Dedicated storage | 632GB |
| External IP | 1 |
| Load Balancer | 1 |
These values are the minimum recommended starting point. Your actual values will depend on many factors, such as the number of topics, payload size, etc. Use these recommendations as the starting point for your own project. Then, run through a series of functional and performance tests to adjust your settings.
Virtual machine configurations
The following are the recommended parameters for the VMs:
| Assets | CPU | RAM |
|---|---|---|
| Master nodes | 2 | 8 GB |
| Worker nodes | 16 | 32 GB |
Storage
We recommend using SSD disks with low latency. The storage is used by the Kafka, Zookeeper, and MariaDB pods.
The following table summarizes the minimum recommended storage for each component, but your configuration will depend on your usage and other parameters.
| Component | Size per pod |
|---|---|
| MariaDB | 8 GB |
| Kafka | 200 GB |
| Zookeeper | 8 GB |
Load balancer
A load balancer is required in front of the cluster. We use the Kubernetes object called ingress controller, which is responsible for fulfilling the ingress rules. A NGINX ingress controller is, by default, deployed with our Helm chart installation. For better performance, we recommend you to use an L4 Load balancer. For more information, see your Cloud provider documentation to configure the load balance, for example, AWS Load Balancing.
Network
The network deployment uses only one subnet per availability zone. Each subnet must be protected by a firewall with appropriate inbound and outbound rules. The following table describes these rules.
| ID | Description | From | To | Protocol | Ports |
|---|---|---|---|---|---|
| 1 | Connection from internet/intranet | Internet/Intranet | Load Balancer | TCP | 80,443 |
| 2 | Connection to the K8s cluster | Load balancer | All subnets | TCP | 443 |
| 3 | Communication between K8s nodes | All subnets | All subnets | UDP/TCP | * |
| 4 | Egress to pull Docker images | All subnets | Internet/Intranet | TCP | 443 |
| 5 | Egress to connect to topics endpoints | All subnets | Internet/Intranet | TCP | 80,443 |
Time synchronization
For security and maintenance reasons, it is strongly recommended to time-synchronize your Kubernetes pods using the Network Time Protocol (NTP). Pods use the clock of the node they are running on, so you need to time-synchronize the nodes of your Kubernetes cluster.
On AWS, it is recommended to use the Chrony client to synchronize your Linux instances. For more information, see AWS Set time.
Kubernetes considerations
This section focuses on additional Kubernetes objects and configuration inside the cluster to support Axway components. This is a required step before deploying containers.
Deployment options
Some parameters are available only at the creation of the Kubernetes cluster. The first, is a network manager for communication between pods and the second, is a set of strong permissions for Kubernetes.
Network plugin
Streams does not require any specific network CNI. Nevertheless, it quickly becomes more convenient, for example, if you wish to create ingress/egress network policies, or mandatory, when deploying on cloud providers, for example, deployment on internal network topology.
We recommend the use of CALICO with default configuration. The AWS VPC CNI has also been validated with our platform.
RBAC Permission
Kubernetes’ role-based access control (RBAC) is a method of regulating access to your Kubernetes cluster and resources based on the roles of individual users within an enterprise.
Streams requires RBAC to be enabled for secrets management and third-party dependencies, such as NGINX, to fine-tune ingress controller permissions.
It is recommended to set people or application permissions to manage resources:
- Allow Helm to manage resources.
- Allow worker nodes autoscaling.
- Allow specific users to view pods, deploy pods, and access Kubernetes dashboard.
- Allow Kubernetes to provide cloud resources, like storage or load balancer.
This configuration is minimal, and you can define more specific permissions with (ClusterRoles) and (ClusterRoleBindings) in the cluster.
| Description | Type |
|---|---|
| Network CNI mode with a specific plugin (CALICO or Cloud provider) to secure pod connections with other applications or resources inside the cluster | Recommended |
| Secure Kubernetes with RBAC capabilities | Required |
Volumes
Several third-party components of Streams (Kafka/Zookeeper and MariaDB) use Kubernetes PersistentVolumes and PersistentVolumeClaims to enable their persistent storage. The underlying infrastructure must support this feature so that the data is properly stored on disk. This allows Streams to maintain a consistent state and save published data in the event of a component failure.
| Description | Type |
|---|---|
PersistentVolumes provisioner is supported by the underlying infrastructure |
Required |
Namespaces
A namespace allows splitting of a Kubernetes cluster into separated virtual zones.
You can configure multiple namespaces that will be logically isolated from each other.
Pods from different namespaces can communicate with a full DNS pattern (\<service-name\>.\<namespace-name\>.svc.cluster.local). A name is unique within a namespace, but not across namespaces.
A typical usage of namespaces is separating projects and configured objects deployed by different teams.
Axway recommends installing the Streams helm chart in a dedicated namespace. This is a good practice because:
- It makes deployment easier when installing into an existing cluster.
- Resources linked to Streams are isolated into a single logical entity.
- You don’t have to specify the full DNS to call other components, therefore, preventing errors. You can just use a service name (
\<service-name\>).
After the namespace is created, the Streams helm chart can be installed within this namespace by adding option --namespace at the installation stage. However, be aware of the following:
- Not all objects are linked to a namespace. For example, PersistentVolumes.
- NGINX Ingress Controller can process Ingress resources from any namespace. Several annotations, like ingressClass, can be set in the helm chart to keep it under control.
| Description | Type |
|---|---|
| Install Streams in a dedicated namespace | Recommended |
Pod resource limits
As explained in Kubernetes documentation, when you specify a pod, you can optionally specify how much of each resource a container needs. The most common resources to specify are CPU and memory (RAM).
Streams is provided with recommended resource requests and limits. This can be viewed and configured in the values.yaml and values-ha.yaml files under the resources section for each component.
In addition, each Java service defines heap memory management with the help of Java options (Xmx and Xms). This can be found in the values files, under different names depending on service type: heapOpts, jvmMemoryOpts, javaOpts. It is important that Java memory heap is kept smaller than the memory resource limit as the java service also needs to allocate objects in “off heap” memory.
| Description | Type |
|---|---|
| Limit memory and CPU usage to protect the cluster | Required |
| Adjust Java opts (Xms & Xmx) to allocate enough resources to services | Required |
Note
Axway provides the recommended values. Be aware that removing pod and JVM resource limits will result in a non-functional platform.Components health check
Kubernetes provides a very useful feature called probes. There is one probe to check if a pod is ready to be used at startup and another to periodically check if a container is still operational. These probes are respectively called “readiness probe” and “liveness probe.”
Streams uses liveness and readiness probes. Liveness probes allow you to know when to restart a (unhealthy) container, while readiness probes allow you to know when a container is ready to start accepting traffic.
As described in helm chart values files, both kind of probes are configured the same way on Streams microservices, that is:
<microservice-pod>:8080/actuator/health
| Description | Type |
|---|---|
| Implement Kubernetes probes to manage container status in real time | Required |
Nodes labels
The Kubernetes scheduler automatically handles the pod placement, for example, spread your pods across nodes or availability zones, do not place the pod on a node with insufficient free resources, and so on. Ensure that your nodes are configured with proper labels. If your cluster is deployed in a cloud provider, for example, AWS or GCP, these labels are added automatically. Otherwise, you must add the following labels to each of your nodes depending on your K8s cluster version:
Examples for AWS (update the values according to your cluster):
topology.kubernetes.io/region=us-east-1topology.kubernetes.io/zone=us-east-1c
Moreover, if you want to force the Streams pods to run only on specific nodes, you can use nodeSelector.
To configure labels, you must first add the labels of your choice to the selected nodes. For example, you can use the label application=streams:
kubectl label nodes <node-name> application=streams
Then update the values.yaml file (using the previous example, for the Streams pods):
nodeSelector:
application: streams
You must define the labels for each of the third-party pods (NGINX, Kafka, Zookeeper, and MariaDB):
nginx-ingress-controller:
nodeSelector:
application: streams
[...]
defaultBackend:
nodeSelector:
application: streams
[...]
embeddedKafka:
nodeSelector:
application: streams
zookeeper:
nodeSelector:
application: streams
[...]
embeddedMariadb:
master:
nodeSelector:
application: streams
slave:
nodeSelector:
application: streams
[...]
| Description | Type |
|---|---|
| Dispatch Streams pods across available nodes (monitoring node can be excluded from this rule) | Recommended |
Affinity and anti-affinity mode
You can optionally use the Kubernetes podAntiAffinity feature to instruct Kubernetes to avoid the scheduling of the same replicas on the same node. Axway does not provide a default affinity configuration but this can be defined in the helm chart values file thanks to the field affinity: {}.
| Description | Type |
|---|---|
| Dispatch Streams thanks to podAntiAffinity option | Optional |
Autoscaling
To properly increase or decrease the number of runtime components to accommodate a workload, there are two scaling techniques used in the reference architecture:
- Nodes/VMs autoscaling
- Kubernetes pod autoscaling
Node scaling
If the allocated number of nodes/VMs is not enough for increasing traffic, there are different ways to scale them. We recommend using a platform-provided mechanism to control this. AWS offers the Auto Scaling Groups feature. There are many ways to design autoscaling. We recommend the Cluster Autoscaler tool, which add a new node when the Kubernetes scheduler cannot schedule a new pod on the any existing nodes.
Horizontal Pod Autoscaler
Using Kubernetes Horizontal Pod Autoscaler (HPA) you can automatically scale the number of components. HPA uses a control loop that checks selected utilization metrics every 15s (default value). There are several options for triggering autoscaling. The average CPU utilization can be used. It is set to a high enough value for optimal resource usages. When CPU utilization exceeds this threshold, Kubernetes adds more pods. You need to test what should be a good CPU utilization based on your pod startup time, traffic pattern and potential impact on the overall performance. An average CPU utilization of 75 percent is a good starting point. Keep in mind that to get HPA working, you need to define resource limits (note, that the default CPU limit is 2cpu). This is an example of this setting in Helm:
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 75
We do not provide any specific guidelines for using Horizontal Pod Autoscaler with Streams yet.
| Description | Type |
|---|---|
| The number of replicas is set manually in the values file and must be tuned depending on the expected load | Recommended |
External traffic
We use the NGINX Ingress Controller to expose both management and subscription APIs. NGINX Ingress Controller automatically creates a load balancer in the cloud provider infrastructure so that the APIs can be reached from the outside using the load balancer DNS hostname. Once known, this hostname must be updated in the ingress resource helm parameter ingress.host.
SSL/TLS is enabled by default on NGINX Ingress Controller unless you have explicitly disabled it (ingress.tlsenabled=false).
The ingress controller handles the SSL/TLS termination thanks to a certificate stored in a k8s secret (refer to the Ingress TLS settings documentation for further details).
| Description | Type |
|---|---|
| Need specific DNS entry to route requests | Required |
| Terminate TLS at ingress level | Recommended |
Secrets
Without secrets, all passwords are set in clear in Manifest. Kubernetes define “secret” objects to encode in base64 all sensitive information. Using Kubernetes Secrets is very useful for variables in containers, Docker registry login, and technical token for shared storage. The following list of secrets relate to the Streams installation:
| Description | Name | Type |
|---|---|---|
| docker registry credentials | my-registry-secret-name | kubernetes.io/dockerconfigjson |
| mariadb credentials | streams-database-passwords-secret | Opaque |
| mariadb encryption | streams-database-secret | Opaque |
| kafka truststore credentials | streams-kafka-client-jks-secret | Opaque |
| kafka credentials | streams-kafka-passwords-secret | Opaque |
| kafka service account | streams-kafka-token | kubernetes.io/service-account-token |
| NGINX tls certificates | streams-ingress-tls-secret | kubernetes.io/tls |
| NGINX service account | <releasename>-nginx-ingress-controller-token | kubernetes.io/service-account-token |
| helm release internal info | sh.helm.release.v1.<releasename>.v1 | helm.sh/release.v1 |
Streams implementation details
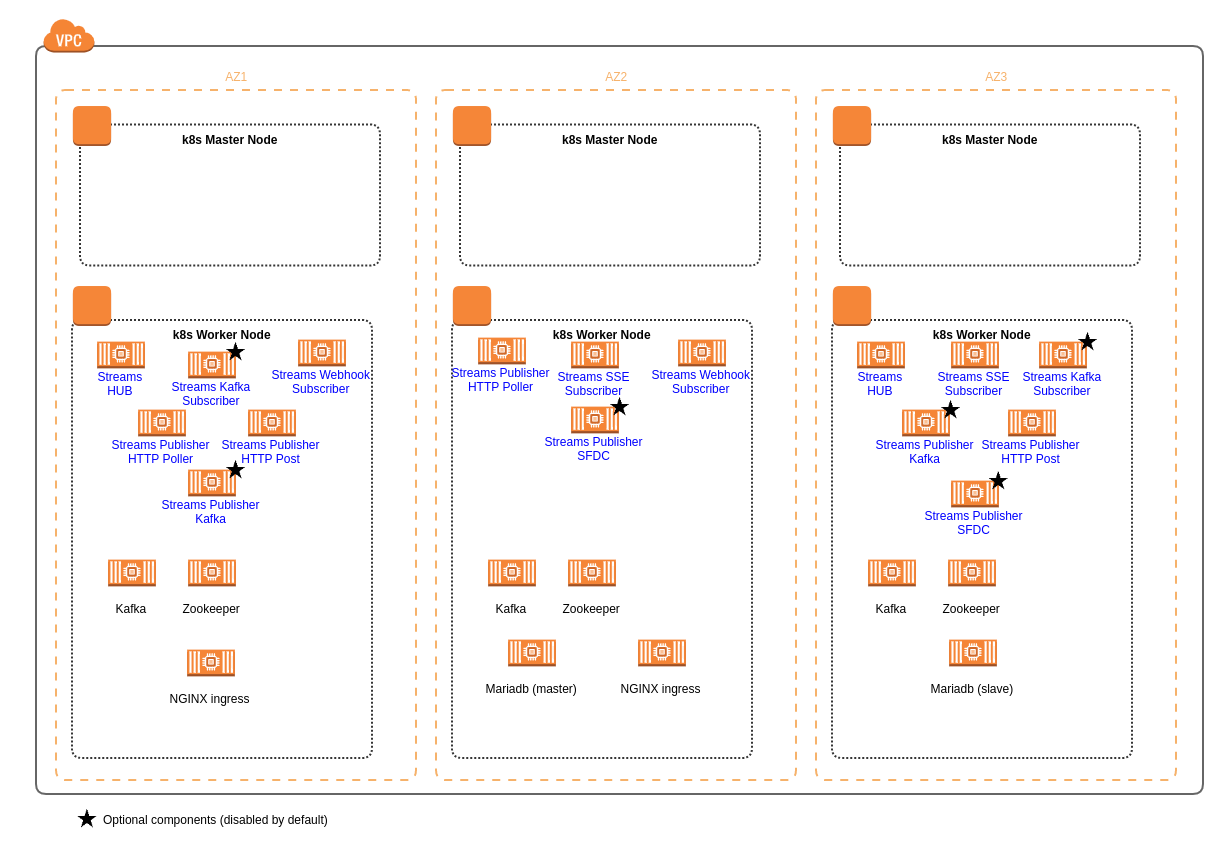
All Streams pods are installed into Kubernetes worker nodes. The master nodes are dedicated to Kubernetes infrastructure management. The diagram above may not reflect exactly your deployment because the K8s scheduler will automatically perform the pod placement across nodes (e.g., spread your pods across nodes, not place the pod on a node with insufficient free resources, etc.).
SSE Subscriber
The SSE Subscriber enables Streams to push data to subscribers (e.g., client applications) through Server-Sent-Events protocol. Server-Sent-Events is a unidirectional http-based protocol which keeps the connection open in order for the server to push data in real time to the client.
- It exposes an API for subscribing to a Streams topic.
- It consumes data from the streaming backbone, which is managed by Apache Kafka.
- It exposes an http port (8080 by default) to expose the subscription endpoint for external consumption.
- It is accessed only through the NGINX Ingress Controller.
To start this pod, the following requirements must be met:
- Apache Kafka up and running
Pod characteristics of the SSE Subscriber for HA deployment mode:
- Healthcheck: LivenessProbe and ReadinessProbe, available at path:
/actuator/health - Kubernetes object: deployment
- Exposed traffic http port by default: 8080 (can be modified during installation)
- Resource limits: 2 CPUs & 3 GB
- Xms & Xmx: 2 GB
- Auto-scaling: no
- Replicas: 2
Webhook Subscriber
The Webhook Subscriber allows external clients to be notified via HTTP Post requests made by Streams to the endpoint that was provided during their subscription.
- It exposes an API endpoint to manage webhook subscriptions.
- It provides an OpenAPI description, available at path
/openapi.yaml. The API is accessible only through the NGINX Ingress Controller. - It uses MariaDB to store the subscriptions created via the subscription API.
- It consumes data from the streaming backbone, which is managed by Apache Kafka.
- It uses Zookeeper as service discovery and for distributed locks.
To start this pod, the following requirements must be met:
- MariaDB up and running
- Apache Kafka up and running
- Zookeeper up and running
Pod characteristics of the subscriber webhook for HA deployment mode:
- Healthcheck: LivenessProbe and ReadinessProbe, available at path:
/actuator/health - Kubernetes object: deployment
- Exposed traffic http port by default: 8080 (can be modified during installation)
- Resource limits: 2 CPUs & 3 GB
- Xms & Xmx: 2 GB
- Automatic scalability: No
- Replicas: 2
Kafka subscriber
Streams Kafka subscriber allows to route events published to a Streams topic to an external kafka cluster.
- It exposes an API endpoint to manage Kafka subscriptions.
- It provides an OpenAPI description, available at the path
/openapi.yaml. The API is accessible only through the NGINX Ingress Controller. - It uses MariaDB to store the subscriptions created via the subscription API.
- It consumes data from the streaming backbone, which is managed by Apache Kafka.
- It uses Zookeeper as service discovery and for distributed locks.
To start this pod, the following requirements must be met:
- MariaDB up and running
- Apache Kafka up and running
- Zookeeper up and running
Pod characteristics of the subscriber Kafka for HA deployment mode:
- Healthcheck: LivenessProbe and ReadinessProbe, available at path:
/actuator/health - Kubernetes object: deployment
- Exposed traffic http port by default: 8080 (can be modified during installation)
- Resource limits: 2 CPUs & 3 GB
- Xms & Xmx: 2 GB
- Automatic scalability: No
- Replicas: 2
Hub
The Hub is the core component of our streaming backbone managed by Apache Kafka. Thus, it consumes data from Kafka and produces transformed data (e.g., incremental updates) that will be consumed by subscribers.
- It exposes an Http port (8080 by default) to expose the API endpoint for topic management.
- It provides an OpenAPI description available at the path
/openapi.yaml. It is accessed only through the ingress controller. - It is in charge of data processing/transformation (e.g incremental updates computation) of the data published by the different publishers.
- It requires MariaDB to store topics. For caching mechanism.
To start this pod, the following requirements must be met:
- MariaDB up and running
- Apache Kafka up and running
Pod characteristics of the hub for HA deployment mode:
- Healthcheck: LivenessProbe and ReadinessProbe available at path:
/actuator/health - Kubernetes object: deployment
- Exposed traffic http port: 8080 (can be modified during installation)
- Resources limit: 2 CPUs & 3 GB
- Xms & Xmx: 2 GB
- Automatic scalability: no
- Replicas: 2
HTTP-Poller Publisher
The Http-Poller Publisher has the capability to poll a target URL at a given polling period for a dedicated Streams topic. The data retrieved from each polling are then published into the Streams platform.
- It uses MariaDB to store publisher contexts.
- It publishes data to the streaming backbone, which is managed by Apache Kafka.
- It uses Zookeeper as a service discovery and for distributed locks.
To start this pod, the following requirements must be met:
- MariaDB up and running
- Apache Kafka up and running
- Zookeeper up and running
Pod characteristics of the HTTP-Poller Publisher for HA deployment mode:
- Healthcheck: LivenessProbe and ReadinessProbe available at path:
/actuator/health - Kubernetes object: deployment
- Resources limit: 2 CPUs & 3 GB
- Xms & Xmx: 2 GB
- Automatic scalability: no
- Replicas: 2
HTTP-Post Publisher
The HTTP-Post Publisher allows any external component capable of performing an HTTP Post request to publish payloads in a Streams topic.
- It exposes an API (8080 by default) to publish payloads into the Streams platform.
- It provides an API description via an OpenAPI spec file at path
/openapi.yaml. The API is accessible only through the ingress controller. - It uses MariaDB to store publisher contexts.
- It publishes data to the streaming backbone (Apache Kafka).
- It uses Zookeeper as a service discovery and for distributed locks.
To start this pod, the following requirements must be met:
- MariaDB up and running
- Zookeeper up and running
- Apache Kafka up and running
Pod characteristics of the publisher http post for HA deployment mode:
- Healthcheck: LivenessProbe and ReadinessProbe available at path:
/actuator/health - Kubernetes object: deployment
- Exposed traffic http port: 8080 (can be modified during installation)
- Resources limit: 2 CPUs & 3 GB
- Xms & Xmx: 2 GB
- Automatic scalability: no
- Replicas: 2
Kafka Publisher
The Kafka Publisher acts as a consumer of an external Kafka cluster. It consumes a configured Kafka topic from the external Kafka cluster and publishes payloads in the Streams platform.
- It uses MariaDB to store publisher contexts.
- It publishes data to the streaming backbone (Apache Kafka).
- It uses Zookeeper as a service discovery and for distributed locks.
To start this pod, the following requirements must be met:
- MariaDB up and running
- Apache Kafka up and running
- Zookeeper up and running
Pod characteristics of the publisher kafka for HA deployment mode:
- Healthcheck: LivenessProbe and ReadinessProbe available at path:
/actuator/health - Kubernetes object: deployment
- Resources limit: 2 CPUs & 3 GBs
- Xms & Xmx: 2 GB
- Automatic scalability: no
- Replicas: 2
Salesforce publisher
The Salesforce (SFDC) Publisher provides the capability to capture changes Salesforce Streaming API PushTopics or Salesforce Platform Events. PushTopics provide the ability to subscribe to change events related to Salesforce Objects (SObjects). Platform Events allow Salesforce users to define their own publish/subscribe events. Once integrated with Streams, Salesforce events can be then broadcast by any of Streams subscribers.
- It uses MariaDB to store publisher contexts.
- It publishes data to the streaming backbone (Apache Kafka).
- It uses Zookeeper as a service discovery and for distributed locks.
To start this pod, the following requirements must be met:
- MariaDB up and running
- Apache Kafka up and running
- Zookeeper up and running
Pod characteristics of the publisher SFDC for HA deployment mode:
- Healthcheck: LivenessProbe and ReadinessProbe available at path: /actuator/health
- Kubernetes object: deployment
- Resources limit: 2 CPUs & 3 GB
- Xms & Xmx: 2 GB
- Automatic scalability: no
- Replicas: 2
Summary table
| Component | Exposes API | Exposed Port | Resources Limits | Xms & Xmx | Requires | Ingress traffic | Egress traffic |
|---|---|---|---|---|---|---|---|
| SSE Subscriber | Yes | 8080 | 2 CPUs 3 GB | 2 GB | Kafka | Yes | No |
| Webhook Subscriber | Yes | 8080 | 2 CPUs 3 GB | 2 GB | MariaDB, Kafka, Zookeeper | Yes | Yes |
| Kafka subscriber | Yes | 8080 | 2 CPUs 3 GB | 2 GB | MariaDB, Kafka, Zookeeper | Yes | Yes |
| Hub | Yes | 8080 | 2 CPUs 3 GB | 2 GB | MariaDB, Kafka | Yes | No |
| Http-Poller Publisher | No | none | 2 CPUs 3 GB | 2 GB | MariaDB, Kafka, Zookeeper | No | Yes |
| Http-Post Publisher | Yes | 8080 | 2 CPUs 3 GB | 2 GB | MariaDB, Kafka, Zookeeper | Yes | Yes |
| Kafka Publisher | No | none | 2 CPUs 3 GB | 2 GB | MariaDB, Kafka, Zookeeper | No | Yes |
| Salesforce Publisher | No | none | 2 CPUs 3 GB | 2 GB | MariaDB, Kafka, Zookeeper | No | Yes |
Third parties
The third-party tools in this section, work integrated with Streams architecture.
Kafka
Apache Kafka is used as stream-processing layer.
Source Docker image:
- Repository: bitnami/kafka
- Tag: 2.8.1-debian-10-r179
Pod name: streams-kafka.
Pod characteristics for HA deployment mode:
| Replicas | CPU | Memory | Xms & Xmx | Persistence |
|---|---|---|---|---|
| 3 (one in each AZ) | 1 | 4 GB | 3 GB | 200 GB |
ZooKeeper
Apache ZooKeeper is used by our microservices and by Kafka (when embedded in installation).
Source Docker image:
- Repository: bitnami/zookeeper
- Tag: 3.7.1-debian-10-r18
Pod name: streams-zookeeper
Pod characteristics for HA deployment mode:
| Replicas | CPU | Memory | Xms & Xmx | Persistence |
|---|---|---|---|---|
| 3 (one in each AZ) | 1 | 512 MB | n/a | 8 GB |
MariaDB
MariaDB is our persistence layer.
Source Docker image:
- Repository: bitnami/mariadb
- Tag: 10.4.24-debian-10-r47
Pod names:
streams-database-masterstreams-database-slave
Pod characteristics for HA deployment mode:
| Name | Replicas | CPU | Memory | Xms & Xmx | Persistence |
|---|---|---|---|---|---|
| MariaDB master | 1 | 1 | 1024 MB | n/a | 8 GB |
| MariaDB slave | 1 | 1 | 1024 MB | n/a | 8 GB |
Note
MariaDB is deployed in master/slave mode with asynchronous commit for replication but the failover is not done automatically.NGINX
NGINX is the ingress controller in front of Streams APIs.
Source Docker image:
- Repository: bitnami/nginx-ingress-controller
- Tag: 1.1.2-debian-10-r27
Pod name: streams-nginx-ingress-controller
Pod characteristics for HA deployment mode:
| Replicas | CPU | Memory | Xms & Xmx | Persistence |
|---|---|---|---|---|
| 2 | 2 | 2048 MB | n/a | 8 GB |
Database considerations
Streams manages 2 types of connection pool for the database:
- Tomcat:
- At several microservices startup, schema database management (liquibase) creates a connection pool with 10 parallel connections. Using these connections (with user root), database tables are created/updated if needed in order to reach the expected state for the current version. Then, the connections are closed and the microservices can resume regular startup.
- Hikari:
- Each microservice, which depends on the database, maintains a connection pool of
maximumPoolSizethreads (default: 10). Connections are established using user streams. When a database call needs to be performed (e.g. topic creation, liveness probe…), either an existing idle connection is available and used for this call, or all the connections in the pool are already in use and the call is queued duringconnectionTimeout(default: 25s). - A connection remains in the pool during
maxLifetime(default: 280s). When maxLifetime is reached and if the connection is not in use, it will be dropped from the pool and a new one will be created in order to keep the pool size atmaximumPoolSizeconnections.
- Each microservice, which depends on the database, maintains a connection pool of
For the best performance with Streams, MariaDB should be configured as follows:
-
- Any connection to the database that stays idle during this value will be destroyed.
- 5 minutes is recommended so that reconnections are not too frequent and zombie connections that are due to potential k8s pod / node crashes can be managed in a timely manner.
- Remember to set your Streams installation
maxLifetimebelow this value. For instance, a microservice connection will die after remainingmaxLifetimeseconds in the pool, but if a pod crashes and the connection cannot be closed properly aftermaxLifetime, it will eventually be destroyed afterwait-timeout.
-
- This value is set to 500 by default for HA setup.
- The formula to compute the number of connections maintained by Streams platform is:
streams_db_connections = (number_of_pods_depending_on_db) * (maximumPoolSize) Example: Assuming a platform deployed with hub, webhook subscriber, http post publisher with 2 replicas each: number_of_pods_depending_on_db = (hub*2+post*2+webhook*2) = 6 streams_db_connections = 6 * 10 = 60- Also take into account the expected load on the platform, which may lead to an increase in the number of microservice replicas. It is recommended to compute the
streams_db_connectionswith the highest number of pod replicas expected so that the platform can properly handle peak load. Several connections are also established by MariaDB (five for InnoDB and one for replication). A safety margin must also be considered in case of a k8s pod or node crash where zombie connections would be held duringwait-timeoutwhile pods are being re-created along with their connection pool.
Refer to the Embedded MariaDB tuning documentation for further details on setting all these parameters in the Helm Streams installation.
Logging/tracing
Logs for a pod are accessible via Kubernetes API:
kubectl logs -f POD_NAME -n NAMESPACE
All logs generated by Streams microservice (excluding third-parties) are in JSON format. There are 2 types of logs:
- Operational logs with LOG marker
- Metric logs with METRIC marker
Operational logs
Each log contains attributes always present:
| JSON attribute | Value |
|---|---|
| dateTime | Date & time of log in ISO 8601 format |
| marker | LOG |
| level | TRACE | DEBUG | INFO | WARN | ERROR |
| message | Content of the log message |
| loggerName | Name of the used logger |
| threadName | Name of the used thread |
| threadId | Id of the used thread |
and others depending on the context:
| JSON attribute | Value |
|---|---|
| topicId | Id of the associated topic |
| publisherType | http-poller | http-post | kakfa |
| publisherId | Instance id of the associated publisher |
| pipelineId | Id of the published data |
| subscriberType | sse | webhook |
| subscriberId | Instance id of the associated subscriber |
| subscriptionId | Id of the associated subscription |
| subscriptionMode | snapshot-only | snashot-patch |
Example
{
"dateTime":"2020-04-22T20:31:17,489Z",
"marker":"LOG",
"level":"INFO",
"message":"Subscription created",
"subscriberId":"16efa8a6-4bbe-4b3e-8d67-23fde3475c8a",
"subscriberType":"sse",
"subscriptionId":"9ebcbd46-ed39-40cc-9ac1-2587dd7efdb8",
"subscriptionMode":"snapshot-only",
"topicId":"354418ce-5dea-42ea-a82a-ac0bd4da631d",
"loggerName":"com.axway.streams.subscriber.service.SubscriptionServiceImpl",
"threadName":"reactor-http-epoll-1",
"threadId":"145"
}
Configuring log level
An unexposed API is available for each Streams microservice to manage logging level during runtime.
To know current logging level, run this command on a microservice pod:
curl -s “http://localhost:8080/actuator/loggers/com.axway.streams”
To change logging level, execute on the chosen pod the following command:
curl -i -X POST -H 'Content-Type: application/json' -d '{"configuredLevel":"DEBUG"}' http://localhost:8080/actuator/loggers/com.axway.streams
Metric logs
Each metric always contains the attributes always present:
| JSON attribute | Value |
|---|---|
| dateTime | Date & time of metric in ISO 8601 format |
| marker | METRIC |
| level | INFO |
| metric | Id of the metric |
and specific attributes concerning each metric:
subscription.started
| JSON attribute | Value |
|---|---|
| metric | subscription.started |
| topicId | Id of the concerned topic |
| subscriptionId | Id of this subscription |
{
"dateTime": "2020-04-22T20:30:12,021Z",
"marker": "METRIC",
"level": "INFO",
"metric": "subscription.started",
"subscriptionId": "0419f74f-f351-43fe-9a1a-2430dfa95722",
"topicId":"329f2ab6-a9bb-4840-a4fd-626e9c2c3216"
}
subscription.ended
| JSON attribute | Value |
|---|---|
| metric | subscription.ended |
| topicId | Id of the concerned topic |
| subscriptionId | Id of this subscription |
{
"dateTime":"2020-04-22T20:30:31,312Z",
"marker":"METRIC",
"level":"INFO",
"metric":"subscription.ended",
"subscriptionId":"0419f74f-f351-43fe-9a1a-2430dfa95722",
"topicId":"329f2ab6-a9bb-4840-a4fd-626e9c2c3216"
}